
Secure Development Lifecycle for Open Source Usage
by Yaron Hakon
Preface
How do we adjust the SDL (Security Development Lifecycle) process for the growing use of open source in internal/external systems we develop and maintain?
This is a question I hear a lot lately from our customers in some recent SDL projects we (AppSec Labs) carried out for our customers.
After we did some research, we didn’t find any reference to the words “open source” in the SDL process bible (you can find the bible here: https://www.microsoft.com/en-us/sdl/), or anywhere else (we did find some small comments but nothing we can use in practice).
So the question is still valid, do we need to make some changes and adjustments to the current SDL process that is under our responsibility or not? If the answer is yes what adjustments do we have to make?
In this article I will explain how to enrich the existing SDL process so it can provide answers to the special security needs of open-source code projects, I will refer specifically to open-source subjects and less to general SDL process steps for in-house code development.
I will try to clarify the changes we need to implement from an application security perspective and the challenges we face when we need to adjust the SDL process to open-source use.
At first, I will quickly explain what an SDL process is, I will list some of the main risks of using open-source code, and the last section will explain how we think we should adjust the process for open source code integration.
Important note! This article is not about how to implement an SDL process in an open source project. This is a different challenge, which is worthy of other article, another day…
SDL Process – Overview
On a high level, the SDL process is a security procedure that is integrated into our development process and which adds tasks, issues, tools, processes, tests, etc. for ensuring application security is under control and referenced from beginning to end in the project.
The main propose of the process is to focus all application security efforts from the beginning of a project in order to reduce the cost of fixing security bugs at a later stage.
Without an SDL process, security bugs tend to be discovered one day before the release in the best case (when we need to perform a PT), or after the project is in production and was hacked by bad people on a bad day J, in which case the cost of fixing the bug comes in addition to potentially losing some customers.
The SDL bible explains the process: “The Security Development Lifecycle (SDL) is a software development process that helps developers build more secure software and address security compliance requirements while reducing development cost.”
Moreover, there are some other good explanations that we can find on the web for what SDL is, how to adopt the process and so on.
The steps for an SDL process are illustrated in the following diagram (taken from the bible):

For a full description of the process, you are welcome to take a look at the bible itself at the following link: https://www.microsoft.com/en-us/sdl
Open source security risks
Are there any security risks in using open-source code? First, we should ask ourselves what the difference is between open-source code and code we develop in-house.
Let’s try to answer that:
- In open-source code projects we do not take part in the requirement stage. We do not define the requirements, although open-source code can be adjusted to the system requirements – which is the reason we would want to use open-source code. Having said that, it is possible that some of our requirements will be different and sometimes we find ourselves above or beneath the right threshold for us. Of course we can characterize new requirements, but no one can promise us that these requirements will be met.
- We are not a part of the planning and design stages of the code in the world of open-source code – that is a stage we are not a part of, we need to take the design as a finalized product and embed it in our design. We can characterize the planning and redesign or improve an existing design, but it is not clear if it will be accepted, or if we will even see any of it in the near future.
- We are not a part of the development process, the whole idea about open-source code is that we do not develop the code but use what there is, of course we can develop and enhance the source code, we will discuss that too.
- We are not a part of the testing process, it is true that in the world of open-source code anyone can contribute to the code or test the code for the project, but once a problem is detected it is not clear when it will be fixed, since the changing and correction cycle of open-source code is at the mercy of the project and not its users.
- We are not a part of the maintenance process – in the world of open-source the entire maintenance process is run by many different bodies rather than being run by a small team, and so it is not sure that problems found in our usage of the code will even be relevant to other users, which means that it is not clear whether fixing the problem will take place within a decent timeframe.
As you can see, the use of open-source code is very different to using code we develop ourselves.
In addition, the information security risk element when using open-source code is in part different to that of using our own code.
The main concern of using open-source code is the fact the open-source code is based on a community of developers and is accessible to anyone – including the hacker community. Let’s break it down a little.
- Security problems resulting from incorrect development – in principle, some might say that open-source code is a lot more secure than code we have developed because “a lot more sets of eyes reviewed this code”. In our opinion, this claim is very problematic especially lately, when we see many security issues with open-source code, and it is the most painful when it happens in projects which are entirely about security such as OpenSSL, projects which have gone through endless testing and still have serious security issues. It is likely that projects which don’t realize a security solution have a substantially smaller amount of security testing, as well as projects with a lower usage-base, meaning the smaller the project, the less security is involved and so the risk that undetected security risks grows.
- Backdoor, paranoid as it may sound, it has been proven in the past that attempts were made to insert malicious code as a backdoor into open-source code projects. There have been, for example, several successful attempts to inset code in Linux (mainly mirror websites, and that’s only what we know of). There is a very high probability that some of the contributors to open-source code projects are, in fact, intelligence agencies or hackers who have added in some ‘special spice’.
- Security bug fix time – when a security issue is discovered in open-source codes it sometimes takes a very long time before an update is released. This is because the update process could be very slow in inappropriate for critical systems which require a particularly high level of defense, also sometimes the update contains other things, or updating the problem requires downloading a new version of the code which may not necessarily support previous versions or may cause problems in the system so you often see clients who don’t update their systems for fear that after updating the integration with their system won’t work.
- Increased attack surface – when we develop code, we usually develop the minimum possible to meet our requirements, but in the world of open-source code, the approach is a little different. Since the code is meant for a large audience, different contributors expand the code so it can handle many situations which are not always required, open code packages expand the code often include lots of functions which is not necessary for each project which uses it. This situation increases the attack surface for the system and sometimes can even jeopardize the entire system in cases where no limitations are set on functions which sometimes create a bypass to an action which we didn’t think about in advance.
- Project expectancy – sometimes projects are simply shut down or purchased by a commercial body in a certain way and then it is not very clear how to perform maintenance on the code when a problem is discovered, or an update is required as a result of incompatibility with the market requirements.
- Everyone can see – especially when we’re talking about code that runs on the server-side. If it is our code, we can assume that apart from the person who wrote the code, or who has access to it, nobody can see and know exactly what we wrote behind the scenes, whereas with open-source code there are no secrets and anyone can see what our background code looks like. This fact can substantially assist in planning a hacking attack on the system.
- Statistics – since there are lots of clients using the same open-source code, the probability of discovering and exploiting a security issue is very high. One issue discovered affects many clients, if for example we are using open-source code as a basis for a number of products we’re developing – the security issue will exist in all of the products. If a hacker finds a security issue in client ‘A’ using open-source code, he can quite easily hack into our systems too. In addition, there are tools which enable a quick search of vulnerabilities through the internet and search engines (in the past there was a Google tool called Google Code Search which actually allowed searching for code lines, and through that also common problems).
- There are probably more risks … (feel free to add them as comments to this article).
Having said all of the above, there are security experts who claim the exact opposite, that open-source code is the safest code because, unlike independent projects which are tested – at best – by a few dozen developers and possibly one security consultant, in open-source code projects each line of code is tested by hundreds of people and many security consultants for free.
On a practical level, at least in our opinion, the truth is somewhere in the middle and it really depends on the type of project. The “richer” the project, the higher the chances are of a fast response to a security incident, and the more people find and respond to problems in the code.
But even when you try to be as realistic as possible, we see that even very “rich” projects like Open SSL, which are used by many security companies and a large number of projects, still have serious security issues which affect everyone.
And so, as a wise Chinese man once said “if you want to be sure the code you’re using is safe, you will probably have to test it yourself”, and as complex as that sounds (and it may well be complex when you have a large project) it is possible (we at AppSec Labs did this process many times for our high risk customers ).
The right way to do this is by combining the use of the open-source code as a part of the SDL process, and providing reasonable security solution for each of the risks presented earlier, based on the threat level.
The threat level should be assessed using models like:
– CIA – Confidentiality, Integrity and Availability of the system and the information
– STRIDE – system’s resilience to attacks like impersonation, tampering, repudiation, information leakage, denial of service, privilege escalation.
– Additional models.
SDL Process Adapted for Use with Open-Source Code
Now we’ve understood that using open-source code is different to using in-house developed code, and that there are different risks associated with it, let’s see how “open-source code” references can be combined into the secure development process to strengthen it.
First, for this to happen, we need to assume that a secure development process takes place, because if it doesn’t how can we combine it (and if there isn’t an SDL process, it is definitely time to start one) ?
The idea is to try and combine defense/testing/control points etc. at every single stage of the SDL.
Important Notes:
- Some developers tends to change the open source code or part of it so it will meet them system requirements, this issue is out of scope, I will only say that when this is the case, we should look at this like any other code we develop in-house.
- In this article I referenced the waterfall SDL, for Agile SDL some customization is needed.
The following is a flowchart demonstrating the process at a high level, with a reference to the “open-source code” subject:
Note: it should be pointed out that the majority of the attention is from the open-source code point of view, there are other angles relating to open-source code which do not appear in the flowchart.
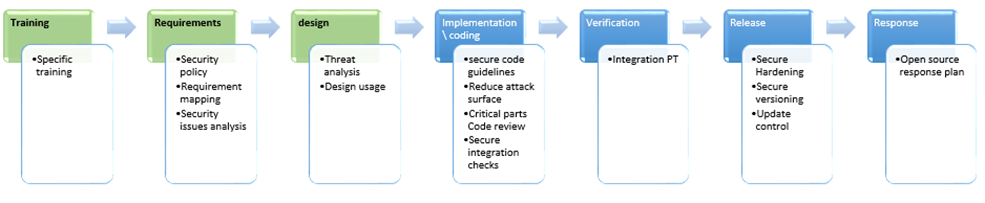
Training Stage:
Preparation stage for each project, it is custom to put the developers through secure development workshops, review of general threats etc.
When we focus on open-source code, the training should be focused and should invoke employee awareness of the following points:
- Open source ≠ safe code. A myth many developers maintain, is that if you use open-source code then there is nothing to worry about and there is no need to think about security – this myth needs to be shattered using examples, which unfortunately there are a plethora of.
- How to correctly use open-source code, where open-source code is downloaded from, how to check the hash, how to download from a place considered safe.
- Focusing the training for projects which use open-source code. It is recommended to review known security issues (if any) in the code, how the general product could have been exploited and attacked through its connection to the open-source code.
- Every code and of course, every open-source code (considered high quality open-source code), can have parameters and settings which enable safe usage of the code (default settings, dangerous functions etc.). Training should be given about what the recommended configurations are, which functions should be used and when and how it is best to combine the open-source code in our product.
Requirements Stage:
This very important stage often doesn’t take place when developing in-house systems. Many systems are created when the only existing requirements are functional ones with no reference to security requirements.
In places where there is reference to security, the following should be noticed:
- Ensure that the project’s security policy includes reference to an open-source code environment and that it defines the security threshold requirements, including defining the process (defining an SDL process for combining open-source code), defining threshold requirements for usage of open-source code and additional requirements such as:
- Open-source code will not be used if it has known security issues of high-critical levels for over one week with no update
- Open-source code will not be used if it doesn’t perform input validation on parameters.
- Which tests are to be performed.
- Update policy – no open-source code will be used if it has known security issues. The most recent update will always be used.
- Bug reporting and management policy etc.
- Confirm that there is no conflict between the security settings of the product and those of the selected open-source code. For example, let’s say we’re developing a product for the US Army, and the army requires that the encryption functions must meet the FIPS 140-2 standard, we must ensure that the open-source code we select meets this standard or we may fail the acceptance tests when a smart consultant tell us “you have failed to meet the system security requirements”.
- Analyze findings/existing problems in the open-source code and how they affect our system, and whether they meet the threshold requirements.
Of course there are other things which should be tested, the security policy can be broadened to work with any additional cases we can think of. In this respect, the security policy is the place to manage and conduct the policy of combining open-source code in our SDL process.
At this point it is highly recommended (if you have not got the internal capabilities) to hire the services of a serious security consulting firm, to provide you with a “credibility report” for the open-source code as well as “usage guidelines”, a service which could save you a lot of money and headaches further down the road.
Design Stage:
True, we’re not going to design how our “open-source code” is going to look because someone else has already done that for us.
But we certainly can and should perform the following:
- Meet all security requirements – correct planning of a system includes meeting the security requirements defined. It is important to confirm that every security requirement has been met in the planning stage.
- Two stage threat analysis:
- Threat analysis/collection of known threats of the open-source code – from different internet sources or performed by security experts.
- Combined threat analysis for our system – combining open-source code in our system creates new threats, we must make sure that for each new threat a satisfactory security solution is in place.
- Determining the usage configuration – since open-source code is supposed to be combined into our code, the usage configuration must be determined in order to ensure it is carried out in a safe manner, for example, assume that the open-source code library handling the files includes three functions:
- File creation.
- File update.
- File deletion.
Also assume that it is clear to us that the users of our system only need to create and update files, it will be correct to nullify access to the “delete file” function in the plans (and later on in the actualization), since it is not required and course open our system to risks we are not prepared to handle at the project planning phase (you don’t always know which open-source code library will be used, and so in the threat analysis phase reference was made only to the creation and editing functions and not to the deletion…).
- Correct combination/implementation – there are challenges in correct combination and implementation of open-source code in our system. For example, if our system contains a permissions module, and our open-source code is a web reporting system and is combined into our system, we must ask ourselves if the permissions module we planned can work in the framework of the open-source code? From experience, unfortunately this question does not get asked enough and from experience in penetration testing we have performed at AppSec Labs, we found that often as a result of combining open-source code it was possible to hack into the system using an innocent module, since there was no enforcement of identification/permissions/input validation etc. during the module implementation.
The result of this process needs to be specific instructions for development teams, on how to integrate and implement the open-source code in the system. Just like any other design instruction including entrance and exit point and controls over the code implementation in the system.
Implementation Stage:
Developers like this stage the most, again, we will probably not really write open-source code, and so we will not be fully performing the main task aimed at the development stage which is “code security tests”, but we are supposed to implement the open-source code into our system. And so we must perform the following actions:
- Act to actualize the open-source code implementation guidelines based on the design documents prepared at an earlier stage.
- Check the requirements – we must keep checking that security requirements haven’t changed (for example, the standard has been updated but the open-source code has not).
- Working with a secure coding guidelines document, customized to the technology and open-source code environment we are actualizing.
- Open source code test – this sounds very serious, but if it is a small code package it is definitely worth considering carrying out some sort of code review (at least automatically) just to feel a little safer, but the recommendation is to test critical parts of the code, for example if we’re using code that actualizes encryption, it would be good to check where the code saves the encryption key, whether a default encryption key is saved which should be changed, etc.
- Code integration check – a security test of the code at every point where our code connects to the open-source code, testing that there are no problems with the code flows in both directions.
Validation Stage:
This is the testers’ favorite stage – the PT security testing stage. It is highly recommended to perform the PT before and after (if possible) the implementation of the open-source code in the system, to see whether the gaps are derived from the added open-source code, or from the system itself.
It is highly recommended to focus the tests on the open-source code components and on the ‘stitches’ between our code and the open-source code (by reviewing the design documents and the threat analysis performed), we need to ensure that all of the problems and solutions which came up during the analysis and planning stages were in fact implemented in a satisfactory fashion.
It is recommended that the tests are carried out in the white/gray approach and that they take place in an environment which reliably represents the production environment.
Sure we need to fix every issue we find in interfaces and ‘stitches’ between our code and the open-source code etc. and if the issue is inside the open source code we should report the issue to the open source project and then decide what to do:
- The project won’t fix the issue, can we processed to production? Should we change the open source code? Should we fix the issue by ourselves? Or maybe we can find a workaround. That is a decision we need to take.
- The project understands and intends to fix the issue – good, then we need to understand if we can wait with production otherwise go back to 1.
Release Stage:
The final actual stage, just before our system meets the clients, is a very important stage. We should carry out some important final actions including:
- Defining hardening, specifically hardening open-source code – which system parameters which are related to the open-source code need hardening, make sure you work according to an organized procedure which has been tested and validated at an earlier stage (testing). It turns out that may systems are hacked because not enough attention was given to this important stage, inaccurate configuration of parameters could result in the system being hacked and there are many examples of this in the internet. It is acceptable in serious companies to provide a hardening document, especially when the system needs to be installed on the client’s network and the developing company has minimal ability to intervene in the actual installation.
- Definition and review of open-source code version update policy (should be a part of the security policy), and an event-response policy for cases in which a security issue is discovered in the open-source code itself or in its connected parts. A procedure must be in place for how to quickly respond to the problem. It is important to understand what the vulnerability level is, and what response is required, in some extreme situations a part of the system or the entire system may need to be shut down. There are some tools that could help with this, for example using infrastructure such as Blackduck (https://info.blackducksoftware.com/wp-know-your-code-LP.html) for the detection of security issues, creating a Dev Op team to be in charge of dealing with these situations and which has the required skills to make an appropriate patch until an update is received from the open-source code team, and which has the knowledge required to implement a patch when it is received from the group as well as other pre-defined tasks in the process of threat-analysis for the system.
It is important to define repetitive security testing cycles in the framework of the security policy based on the risk level. For example, a sensitive system should perform a quarterly security test but a low-threat level system can perform a security test once annually. It is very important to mention the open-source code components in the scope of the tests, so the tester knows to pay attention to these important sections during the test.
- Final Security Review (FSR) – the FSR should implement tests that are related to open-source code, such as:
- a. Confirmation that all security-related bugs have been adequately closed, and that the ones that were not closed do not pose a substantial threat to the system.
- b. Confirmation that singe the security tests there were no changes such as new components, version changes to some of the open-source code sections etc. which require attention.
- c. Confirmation that no security issues were discovered in the open-source code sine it was implemented in the system (sometimes a long time passes between when a version is selected and tests are completed, when everything is ready for release. Sometimes a new version that changes the game is released a week before the launch date and it requires an addition testing cycle on the system or parts of it).
- d. Privacy check – confirmation that usage of the open-source code does not expose the system to user privacy issues.
- Version management – of course it is important to ensure that the accepted version management process will include management of the open-source code versions. In any case it is required that the open-source code version be clear and readily available.
Response Stage:
At this stage we must actualize the security policy we determined.
We will use tools as previously mentioned in order to detect exposures in our open-source code, we will perform periodical penetration tests, we will act according to our update policy should an exposure be detected and will review the system logs in order to proactively try and locate suspicious system-endangering activity, and other required actions defined in the security policy.
In addition of course, when a new activity is required such as developing new functionality, new interface, updating an existing component etc. we must carry out all the actions presented above accordingly, so we don’t actually perform the full SDL process – but certainly the main parts such as threat analysis or code tests, it is very important to update the different documents so they reflect the existing situation.
That’s it, we have completed a short review of what we think should be done when managing an organized SDL process and would like to address the open-source code issue.
Please feel free to leave a comment or send me an email at Yaron@appsec-labs.com, I would love to hear your thoughts.
Good luck SDL Warriors!
Leave a Reply
Want to join the discussion?Feel free to contribute!

i like this article
it’s open my eyes for new issues with open source code i didn’t think off
Thank You!