A Taxonomy on Brute Force Attacks
Brute force attack is a well-known technique of trial and error attempts used by attackers to gain access to unauthorized data. It can be leveraged against servers as an online attack and also against files as a local attack.
The common denominator of all these types is that the same pattern is almost always the same:
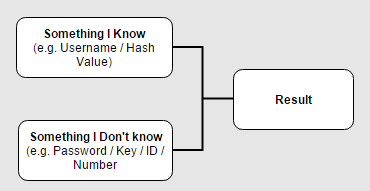
In most cases the attacker would have to know two major keys from the diagram – let’s take for example a common scenario where the attacker tries a brute-force attack on the login interface of an applicaiton in order to find the correct credentials of a certain account. The known keys would be:
- Something I know – In this case, the username of the account that the attacker wants to hijack.
- The result – On each attempt, the attacker receives an indicator of failed/successful result.
The well-known brute-force methods are:
- Dictionary Attack – Brute-force using pre-prepared password dictionaries which are available over the internet and contain dozens (or even more) of Terra-bytes of passwords (!) – according to the diagram shown above, this type of attack will be applicable when we already have the username, and are getting the result after each attempt.
- Rainbow Table – Brute-force attack using pre-prepared hashed password dictionaries – according to the diagram shown above, this type of attack will be applicable when we already have the username and the result, which is the hashed password. So actually rainbow table tries to hash a bulk of plain-text passwords in order to compare their hashed value, to the tested one.
- Search attack – the old school brute-force attack which was used to guess the password using patterns such as regular expressions. This type of attack is less common nowadays thanks to accessible resources of passwords and rainbow-tables.
- Ranged attack – this type of attack is generally used against an application for which the attacker has a list of valid users. It is a brute-force attack on the username field, while the password remains the same.
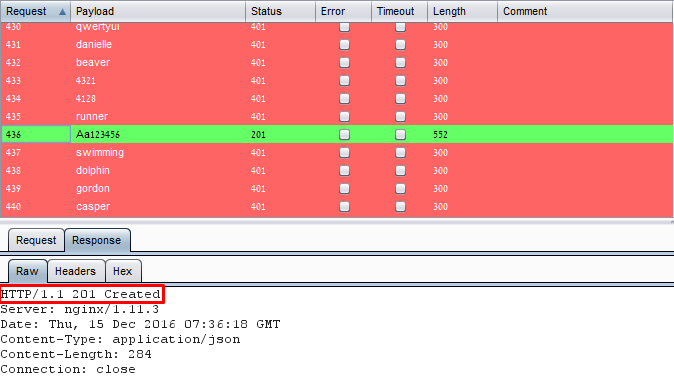
In the image below we can see a brute-force attack. The “Payload” row represent the password sent on each attempted request and the “Status” and “Length” rows that represent the result. As shown in the image, the successful request (#436) received a different response status (201, instead of 401) and length (552, instead of 300).
Let’s address this example to elaborate about brute-force effectiveness under different situations:
Login Interface – Brute-force success rate is directly affected by two assumptions:
- User enumeration – In case the application responds differently whether the account exists in the system or not, we can map the users and target one of them. Some examples of different responses on different interfaces in the applicaiton could be:
- Registration – “This username is already in use” / “Success”.
- Login – “Incorrect Password” / “User does not exist”.
- Account Lockout – “The account is locked” / “Invalid username or password”.
- Forgot Password – “Email was sent” / “Email could not be found”.
- Change Email – “This email is already in use” / “Success”.
- Weak Password Policy – A permissive policy that allows users to pick a simple password which will be easier to find, using a dictionary brute-force attack.
Verification Flows – such as an insecure forgot password / link email to existing account. The idea of these verification flows is to ensure that the user who performs the actions, owns the email he stated. When does it becomes insecure?
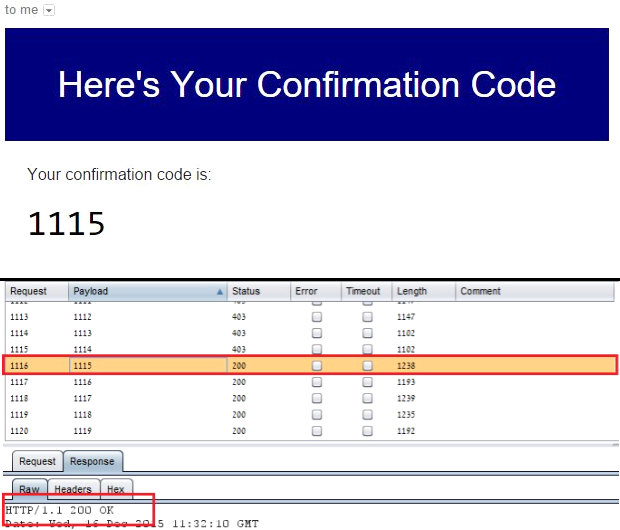
When the application sends a short numeric confirmation code to your email/phone and asks you to type it to prove your ownership. This scenario does not require the attacker to actually access the victim’s email account, but only to know the pin code that has been sent there. For example, the image below shows a brute-force attack on the confirmation code. It can be seen that on the 1,116th attempt, the attacker found the correct code:
Sequential IDs – In case the application uses ID numbers to represent an object (user, invoice number, organization ID etc.) the attacker can also use a search attack and run through a range of numbers to reveal more information. The responses might change according to server-side logics. In case there is no authorization checks, the attacker can reveal valuable information. Another scenario is that the server will not authorize the request, but will confirm that there is an existing resource:
- “User not found” / “Unauthorized”.
- “Organization not found” / “Unauthorized”.
- “Invoice not found” / “Unauthorized”.
Client-Side Authentication – weird right? In some rare cases, where the hashed password is stored on the client-side and the login form executes JavaScript function that hashes the input in the same way and compares the result to the stored value. For that matter, the attacker could use a JavaScript tool to perform client-based brute force (https://appsec-labs.com/portal/embedded-ajax-brute-force-tool/).
Multi-IP Threaded Brute-Force – in the “extreme cases”, where the application blocks our current IP address, the attacker could use some python scripts who use the TOR module to change the IP every couple of requests. This technique is pretty well-known and there are many available tools for that.
Let’s wrap up
Brute force attacks may change according to context, note that there are many tools which can be used to perform this attack and improve its results. Since there are many techniques to attack, keep in mind that there are lots of techniques to mitigate the attack. To read about how to prevent brute-force using common and un-common solutions, view part 2: Brute-force prevention.


Leave a Reply
Want to join the discussion?Feel free to contribute!